Distributed & Parallel Query Execution
Since the inception of the relational database, application engineers and architects have required ever-increasing performance and capacity due to the simple observation that business databases generally grow in size over time. Adding to this trend is the proliferation of business data due to the maturation of the Internet economy, the Information Age and the prevalence of high-volume electronic commerce. Using inMemory+ shared-nothing architecture, large amounts of data can be distributed across a number of machines each with its own CPU, memory, and disk. This technique allows for proper balancing of database size with system resources, resulting in dramatic performance improvements and scalability for a given application. inMemory+ has a high performance query engine which offers increased parallelism compared to conventional databases. When a client sends a query to inMemory+ for processing, it gets executed in parallel on the related slave nodes and the results are combined on the master node and returned to the user. Because queries (especially analytic operations) are run in parallel on different slave nodes, the results are returned many times faster compared to a single monolithic query run on any standard database server.
The solutions for big data usually use MapReduce algorithm for data processing. MapReduce has several drawbacks. MapReduce algorithms use disk-based operations which degrade performance and MapReduce algorithms use long hectic jobs and don't return results in real-time. Also, specialized language learning and training is required to create MapReduce algorithms. inMemory+ overcomes these drawbacks. inMemory+ enhances performance by executing all queries inside memory at each node in real-time. inMemory+ supports Standard SQL which is easy to learn and its syntax is familiar to database users.
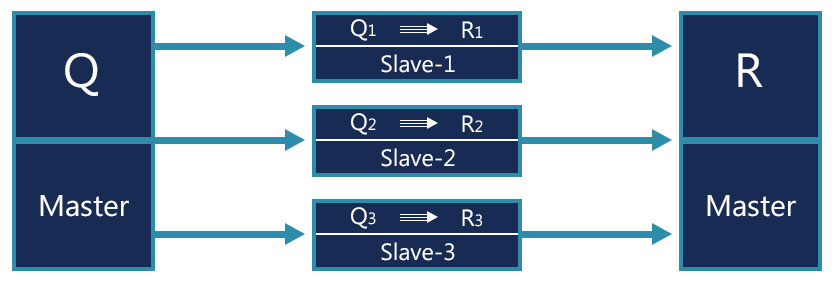
When a query Q is send to the master node for processing it splits them into three queries Q1, Q2 and Q3 and distributes them over the slave nodes, e.g., slave node 1, slave node 2, and slave node 3 respectively. Slave node 1, slave node 2, and slave node 3 execute the query on the data stored in memory and return result R1, R2, and R3 respectively to the master node. Master node combines the result R1, R2, and R3 into a single result R and returns it back to the user.